Guest post by Naila Burney.
A major challenge in video games is to record and manage thousands of dialogue lines. In Mass Effect 3, for example, forty thousand lines were recorded, and in Saints Row: The Third, eighty thousand lines were needed. Having to deal with so much dialogue can be extremely time consuming and expensive. For this reason, I decided to build a prototype of a fictional language dialogue system as a possible solution that would simplify processes and reduce costs. I chose Max/Msp because as a non-programmer, I needed a tool that would allow me to experiment and develop my own rules and behaviors. The high versatility of Max/Msp would let me build the exact design I had in mind.
[vimeo]https://vimeo.com/64538603[/vimeo]
BACKGROUND
Invented languages have been widely used for fictional characters of stories, movies, and video games[1]. These range from highly complex and fully functional, like the Klingon in Star Trek, to nonsensical gibberish that only intends to produce an illusion of a real language (e.g. Simlish, spoken by The Sims, which does not express any literal meaning, but reflects the character’s emotions through intonation [5]). Darren Blondin posted an excellent article about constructed languages (link: http://www.dblondin.com/092507.html) where he analyzes another approach for creating them, which is based on sound design. For animal-like creatures in Star Wars, for example, Ben Burtt recorded sounds of groans and vocalizations of bears, lions, walruses, and dogs. Then, he classified them into categories (angry, happy, and inquisitive) and built a word list. Next, he modified and processed the sounds with pitch variations. Then he added overlapping layers, and finally created phrases by concatenating the sounds [3].
Design Concept
The FLDS creates phrases based on how languages work, by concatenating and recombining sampled sounds (phonemes and morphemes) to build words. Based on probabilities, it creates series of words that play one after the other, with pauses in between. However, it only produces an illusion of a language and has no grammar rules. It uses different settings of pitch, pace, pauses, and volume dynamics to express specific moods. Also, several layers of sounds can be included to add common elements and bind sounds together, providing a natural feel to the language.
Creating an impression of a real language
Real languages have a phonological aspect that determines the way in which words are pronounced. A phoneme is the smallest unit of sound, such as /s/ or /b/. Phonemes are key elements in this system because they can characterize a language and produce a sense of unity. For example, in the Polish language, the most repeated phonemes are “ch,” “sh,” and “dg”, and add a particular seal to it [11]. For alien or creature dialects, instead of phonemes you might want to use unconventional noises, such as clicks (like in District 9), which would be equivalent to these unifying sounds.
The next key component of the system is a morpheme (or main sound). Morphemes are the smallest units of language with a meaning (e.g. car, or reach) [10]. Words can comprise one or more morphemes. Air and line, for instance, can be combined to produce airline. An aspect of morphemes is that they may vary in size (e.g albatross, water, cow). This is appropriate for the system because concatenating sounds at a smaller level, like syllables, would result in fragmented and disjointed words.
Silences or pauses also play an important role in language. They can either be grammatical, to separate phrases from each other, or non-grammatical, such as breathings or filled pauses (e.g. hmm, eh, and uh). The occurrence of pauses depends on different semantic, phonetic, physiological and or cognitive factors. Breaths, for example, are usually physiological longer pauses. Non-breaths might vary depending on speaking rate [16].
The FLDS simulates a structure based on sounds that would correspond to morphemes as the building blocks of a language, specific phonemes or noise clicks as the unifying elements, and pauses to provide articulation to phrases.
Emotional Speech
“A language, or more accurately, the sensation of a language, has to satisfy the audience’s most critical faculties. We are all experts at identifying the nuances of intonation. Whether we understand a given language or not, we certainly process the sound fully, and attribute meaning—perhaps inaccurate—to the emotional and informational content of the speech”.
Ben Burtt [3]
Apparently, humans can perceive emotional tone in the psychophysical qualities of another person’s voice, and different emotions can be expressed in dialogue depending on combinations of volume, tempo, and pitch contour [8]. The mood settings of the FLDS were based on Juslin’s charts that associate several voice tone behaviors with emotions. The system focuses on sad, angry, and happy moods. It also includes neutral as an emotionless state.

Chart by Juslin and Laukka [9] that summarises main patterns of speech depending on the mood.
[vimeo]https://vimeo.com/64543087[/vimeo]
HOW IT WORKS
Overview
The system concatenates events in the following order:
Morpheme (or main sound) – Phoneme (or unifying sound) – Breath (or filled pause) – Delay
Morphemes are compulsory and the other elements are optional. Prior to generating a phrase, the user can configure the settings of these variables and set the mood, which and what percentage of phonemes to include within the words, the percentage of breaths, and the probabilities of obtaining pauses, among others. Then, a sentence length must be specified to define how many times the sequence should be repeated. The mechanism will be explained in more detail below.
Sections
1) Load Folders
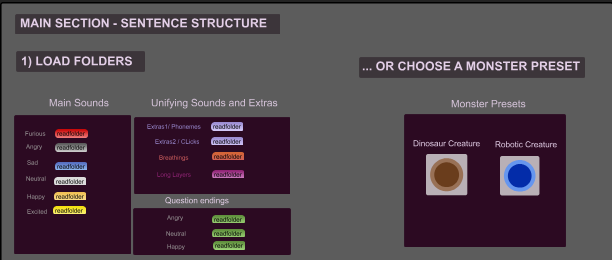
In the first section, the user can load folders with samples classified into main sounds (per moods), question endings, unifying sounds, breaths (or filled pauses), and layers. There is also an option that will automatically load folders of two preset examples.
Under the hood:
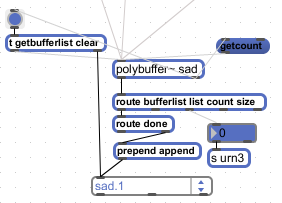
The [polybuffer~] object allows to store and reference multiple sound files from a folder. There is one [polybuffer~] per folder.
2) Configure Phrase Settings
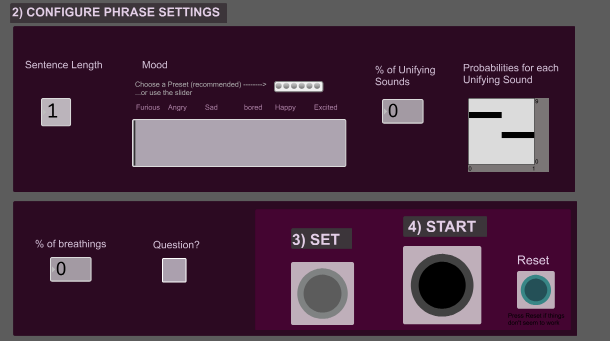
The next section allows to configure the phrase settings. The user can choose the mood, percentage of unifying sounds, probabilities for each type of unifying sound to appear, percentage of breaths in a phrase, probabilities of obtaining pauses, the duration of those pauses, and a question ending option.

Regarding moods, there is a slider that goes from furious to excited. If the happy mood is selected, the sequence will include random files from the happy folder. If the user selects a higher degree of happiness, towards excited, the sequence will include less files from the happy folder and more files from the excited folder. Selecting a mood will also automatically set presets for volume dynamics, pitch, and pace.

Note that all samples are randomly selected from each folder. However, to avoid phrases sounding too repetitive, the system is configured to not generate two equal consecutive morphemes. Each time an [urn] object receives a bang, it evaluates the total number of sound files in a [polybuffer~] and outputs a random number that will never be the same as the immediate previous one, allowing to generate series of numbers without duplicates. A future improvement would be to make this setting optional, in case an alien language is intended to sound repetitive.

3) Create a Series
In order to create a series of MPhBD, a sentence length must be specified that will determine how many MPhBD sequences will be created. For example, if the sentence length is 10, the system will produce a series of 10 MPhBD sequences, (each one with different values but based on the same settings), obtaining, for example, something like this:
MMphMB-MMph-Delay- MphMB-MMphMph
Under the hood:
Once all variables and events are configured, and the sentence length has been specified, the set button must be pressed. This will create the lists of values correspondent to a series. As each MPhBD is based on random and probabilistic choices, all lists and messages of a series are stored into [coll] objects so that they can be recalled in the exact same way any time the user decides to replay a phrase. In more technical words, set sends the sentence length to a [uzi] object that will output the specified number of bang messages to all of the elements of the series stored in [coll] objects.
4) Play the Series (Unpack the lists, and set the grooves)
When start is pressed, the sentence length is sent to a counter. Each time the counter increases, the correspondent MPhBD values stored in [coll] objects are unpacked. The unpacked values are used to set and play five groove objects: one for morphemes, one for phonemes, one for breathings, one for question endings, and one for layers.
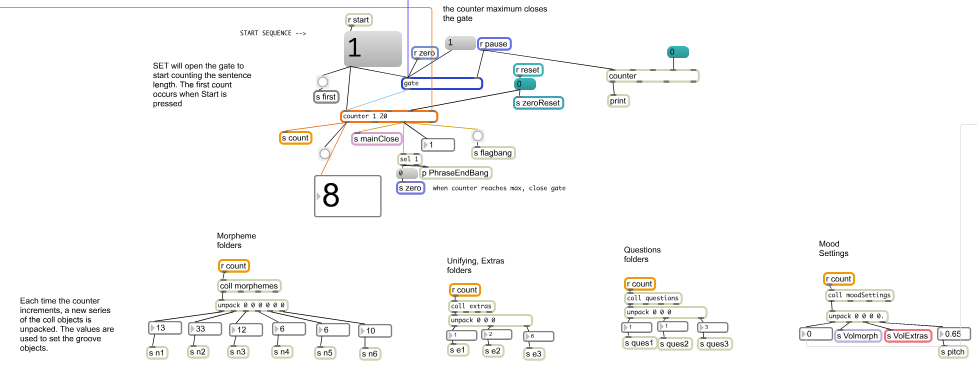
Concatenating sounds and pauses
When the counter starts, the first morpheme is played through the first groove object. Once it is done playing, the groove object outputs a bang (edge bang) that will indicate the next groove to play the next sound. The system is constantly evaluating conditionals to decide which groove should play next.

5. Other
The other section allows to configure independent and global volumes. It also has additional effects; a Delay and Reverb for the main words, a pitch shifter that uses a variable line, and a Global Reverb to bind sounds together.
 |
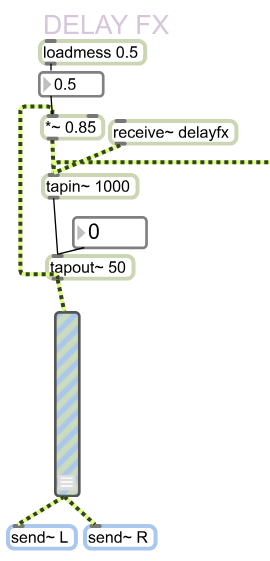 |
||
6. Layers
This section contains global controls for adjusting layers. Any audio file can be used as a layer underneath the main series of morphemes, phonemes, and breathings. The files are played whenever the [peakamp~] object detects a signal from the main sequence.
Depending on the mood, layers have different settings of pitch and pace (which can be scaled). The angry moods, for example, are higher in tone, shorter in duration, and have little pitch variability, giving the impression of sharp and repetitive attacks. The sad and neutral layers are longer, lower in pitch, and more constant (low pitch variability). The happy moods have a wider pitch range, which means that sounds will have higher pitch variability. Also, in the happy moods, pitch changes are triggered at more irregular times (providing more microstructural irregularity) than in the other moods.
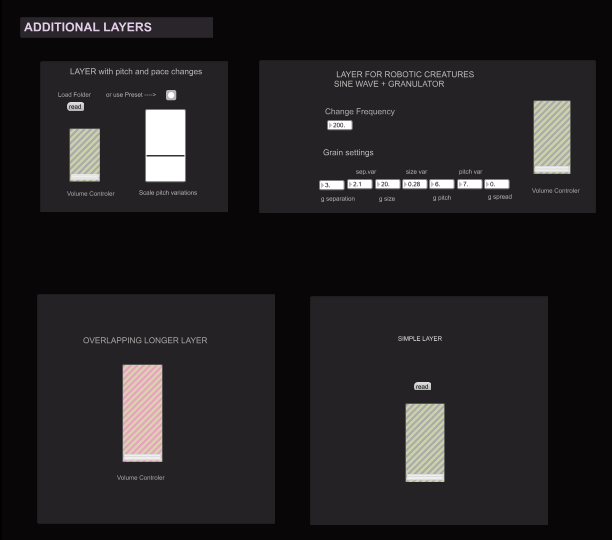
Layer For Robotic Creatures – Sinewave + Granulator
One of the layers is a sine wave that is triggered when [peackamp~] detects signal from the main series of words. The sine wave is altered with a granular synthesis object called [munger~]. Each mood has different settings for the granulator and the decay time of the signal. Similarly to the previous layer, the angry moods sounds sharper, with fast attacks. Sad has longer grain size, and thus, softer and more legato sounds. Neutral mood does not use a granulator, but just the sine wave at a low and constant tone register. The happy moods have more grain pitch variability, grain size variability, and separation.
Layer with longer overlapping sounds
The previous layers are synchronized with the main MPhBD words. A different layer of longer sounds can be added that overlaps with the main words. This can be useful to add commonality and bind sounds together.
7. More Settings

In this section, some of the default settings can be modified. The pace and pitch range for morphemes, phonemes, and breaths can be scaled, and pauses can be configured.
Testing
Fifty two participants were asked to answer questions regarding the mood expressed on eight phrases for two different creatures. The first four phrases correspond to a large animal-creature made of pig vocalizations and other wild animal sounds. The other four phrases correspond to a small alien, and were created with my own voice. Participants were asked to match a mood with a sound file.

The results demonstrated some confusion among participants. In the first creature, for example, sad and neutral moods were often confused. However, sad and neutral have similar pitch and dynamic qualities. Both have a low pitch range, low volume, and low pitch and dynamics variability. In other words, both moods share the same range of arousal, which means, these results are not negative. Similarly, in the second creature, angry was confused with happy, which is apparently opposite, but in truth shares the same arousal dimension. This means that one of the major problems that caused confusion was the intrinsic nature of the sounds. For example, in the first creature, the sad samples were made of gorilla breaths. Even though they are softer than the other samples and have elements that are supposed to be associated with sadness (more legato, lower pitch register and volume, more pauses), listening to a wild animal out of context can bring multiple interpretations. In fact, wild animals are usually associated with threat, and that is why they are sometimes used in film to characterize danger [15].
It would be necessary to analyze other aspects of sound that people associate with mood such as timbre. The sound produced by a kitten, or a bird, might be softer than the gorilla breaths. However, note that choosing the sounds based on mood and timbre associations would imply a restriction for creating the right language, as it would not always fit with the visuals of the character. If the dialogue is generated for Godzilla, it would not be appropriate to use bird sounds. In other words, sounds need to be based on the character of the game. Is it possible to “humanize” sounds, regardless of their nature, and fit them into moods? Are pitch, dynamics, pace, and pauses enough? Probably yes, but in order to prove it, it would be more reliable to test the sound against an image within a context.
Final Thoughts
It might seem ambitious to condense presets of pace, volume and pitch parameters to work generically for various creatures. Each monster will always have its own needs and variants. However, when using Max/Msp, there are endless options that can be added to expand the system and make it more flexible. For example, alternatives for raising or lowering intonation could be implemented (using formant pitch shifting and granular synthesis). The system could also have specific rules for pauses; instead of occurring at random places, they would occur at n% of each phrase (specified by the user). The FLDS would also be more efficient if it had more types of sounds classified into subfolders (e.g. initializing sounds, connector sounds, and ending sounds) and this way, it would provide more smoothness to sentences.
The FLDS is still in a testing and developmental stage. However, although it still has wide room for improvement, it serves to illustrate the potential of Max/Msp as an ideal environment to build your own sound design tools and prototypes.
REFERENCES
[1] Blondin, D. (2007) Language Design for Sound Designers. [Online]. Available from:
http://www.dblondin.com/092507.html
[2] Bridgett, Rob (2009). A Holistic Approach to Game Dialogue Production [Online]. Available from: http://www.gamasutra.com/view/feature/4178/a_holistic_approach_to_game_.php
[3] Burtt, B. (2001) Star Wars: Galactic Phrase Book and Travel Guide. 1st ed. New York: The Random House Publishing Group.
[4] Clark, Herbert H. & Wasow, Thomas. (1998) Repeating Words in Spontaneous Speech. [Online]. Available from: http://www-psych.stanford.edu/~herb/1990s/Clark.Wasow.98.pdf
[5] Ellison, B. (2008) Defining Dialogue Systems. [Online]. Available from:
http://www.gamasutra.com/view/feature/3719/defining_dialogue_systems.php?print=1
[6] Gross, Ariel (2012) 80,000 Lines: Three Lessons Learned. [Online]. Available from:
http://www.gdcvault.com/play/1015913/80-000-Lines-Three-Lessons
[7] Isaza, M. (2009) Exclusive Interview with Dave Whitehead, Sound Designer of District 9. [Online]. Available from:
[8] Juslin, P. Västfjäll, D. (2008) Emotional responses to music: The need to consider underlying mechanisms. [Online]. Available from: http://nemcog.smusic.nyu.edu/docs/JuslinBBSTargetArticle.pdf
[9] Juslin., Laukka. (2004) Expression, Perception, and Induction of Musical Emotions: A Review and a Questionnaire Study of Everyday Listening. [Online]. Available from:
[10] McMahon, A. & Bermúdez-Otero, R. (2006) English phonology and morphology. In:
Aarts, Bas, & McMahon, April (2006). The handbook of English linguistics. Oxford: Blackwell. 382-410. [Online]. Available from:
http://www.bermudez-otero.com/bermudez-otero%26mcmahon.pdf
[11] Nevin, Kelly (2009) Guide to Polish Pronunciation. [Online]. Available from: http://www.nevinkellygallery.com/essays/essay-guide.htm
[12] Pereira, Cécile. (1996) Proceedings of the sixth Australian International Conference on Speech Science and Technology. Angry, Happy, Sad, or Plain Neutral? The identification of vocal affect by Hearing-Aid Users. [Online]. Available from:
http://www.assta.org/sst/SST-96/cache/SST-96-Chapter11-p9.pdf
[13] Purslow, Matt. (2011). Mass Effect 3 contains twice as much dialogue as the first game. [Online]. Available from:
http://www.pcgamer.com/2011/10/13/mass-effect-3-contains-twice-as-much-dialogue-as-the-first-game/
[14] Searle, John R. (2006) What is Language: Some Preliminary Remarks. [Online]. Available from: http://socrates.berkeley.edu/~jsearle/whatislanguage.pdf
[15] Whittington, W. (2007) Sound Design & Science Fiction. Austin, TX: University of Texas Press. p.96, 97
[16] Zvonik, E. 2004. Pausing and the temporal organization of phrases. An experimental study of read speech. [Online]. Available from: ftp://193.1.133.101/pub/fred/docs/zvonikThesis.pdf
Special thanks to Naila Burney for this article. You can finder her on Twitter: @NailaAshi and at gameaudiostuff.com and be.net/nailaburney
amazingly great article….
Wow! What a fantastic article. I’m working creature sound, this has been such an inspiration. Time to crack open Pd-Extended :D
Fantastic concept and a great article as well — thanks for much for sharing! This is inspiring for me, and for my Max students as well. Excellent work!
This is a well written and well researched article. I am hoping to work on some projects in the field of linguistics and audio to preserve dying languages. I would love to create and record a fictitious language for a video game!
Thanks for all the comments, I’m glad you enjoyed the article! If anyone is interested in knowing more details about the project (and work in progress), please don’t hesitate to contact me :)
Thank you very musch for this article!
It’s worth mentioning that this was my final project for the MSc in ‘Sound and Music for Interactive Games’ at LeedsMet Uni. It might be of interest for some! http://courses.leedsmet.ac.uk/sminteractivegames_msc