Guest Post by Tadej Droljc
Introduction
The purpose of this article is to introduce the reader to the subject of Real-Time Sonographic Sound Processing. Since sonographic sound processing is based on windowed analysis it belongs to the digital world. Hence we will be leaning against digital concepts of audio and image or video throughout this article.
Sonographic Sound Processing is all about converting sound into image, using graphical effects on the image and then converting the image back into sound.
When thinking about sound-image conversion we stumble across two immanent problems:
- First one is that images are static while sounds can not be static. Sound is all about pressure fluctuations in some medium, usually air, and as soon as the pressure becomes static, the sound ceases to exist. In digital world, audio signals that may later become audible sounds, are all a consequence of constantly changing numbers.
- The second problem is that image, in terms of data, exist in 2D space, while sound exists only in 1 dimension. Gray scale image for instance can be understood as a function of pixel intensity or brightness in relation to 2 dimensional space, that is width and height of an image. On the other hand audio signal is a function of amplitude in relation to only one dimension, which is time (see fig. 1 and fig. 2).
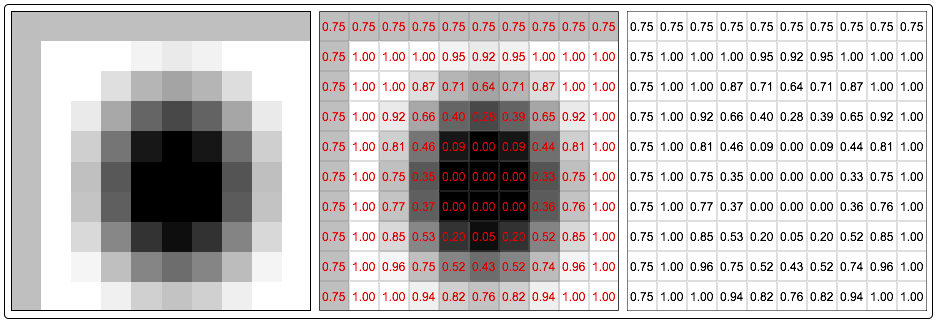
Figure 1 Heavily downsampled image (10×10 pixels) of black spot with gradient on white background. On right-hand side of figure 1 is numerical representation of an image that is two dimensional array or a matrix.
At this point we see that we could easily transform one column or one row of an image into a sound. If our image would have a width of 44100 pixels and height of 22050 pixels and our sampling rate would be set at 44.1 KHz, that would mean that one row would give us exactly one second of sound while one column would give us exactly half second of sound. Instead of columns and rows we could also follow diagonals or any other arbitrary trajectories. As long as we would read numbers (=switch between various pixels and read their values) at the speed of sampling rate we could precisely control the audio with image. And that is the basic concept of wave terrain synthesis, that could also be understood as an advanced version of wavetable synthesis, where the reading trajectory “defines” its momentary wavetable.
So the answer to the first problem is that we have to gradually read an image in order to hear it. So for instance if we would like to hear “the sound of my gran drinking a cup of coffee”, we would need to read each successive column from bottom to the top and in that manner progress through the whole width of the picture (*as mentioned earlier, the trajectory of reading is arbitrary as long as we would read all the pixels of an image only once). That would translate an image, that is frozen in time, into sound, that has some time limited duration. But since we would like to only process some existing sound with graphical effects, we need to first generate the image out of sound.
What we could try for a start is to chop “horizontal” audio into slices and place them vertically so they would become columns. That would give us an image out of sound and as we would read the columns successively from bottom to the top we would actually gradually read the picture from left to right (fig. 3) and that would give us back our initial sound.
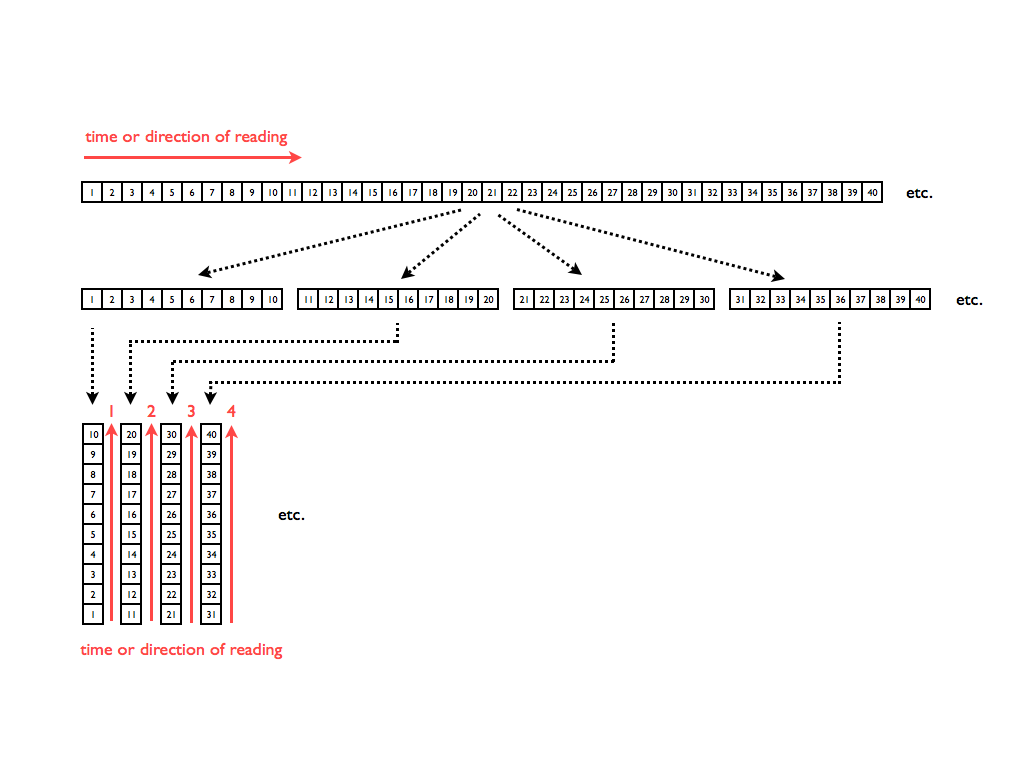
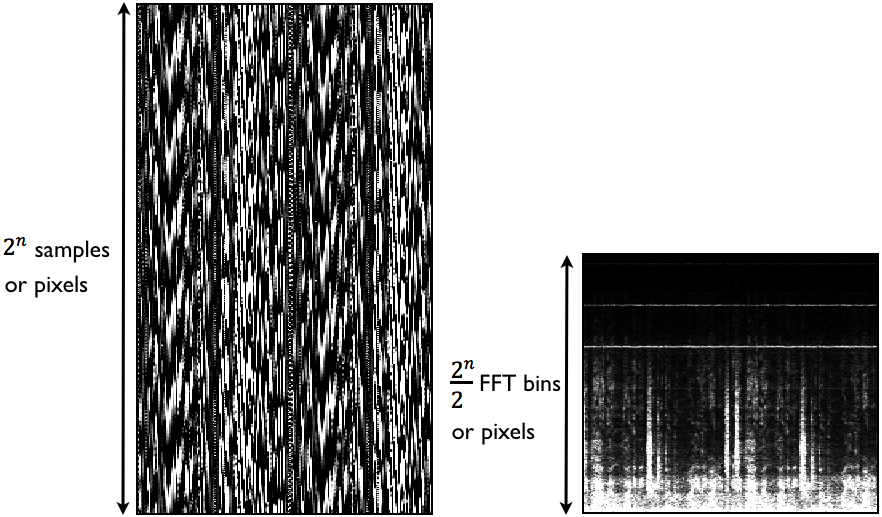
At that point we would actually have an image made out of audio data and we could easily play it back. But that kind of image would not give us any easily understandable information about the audio itself – it would look like some kind of graphical noise (fig. 4a). Hence we would not be able to control the audio output with graphical effect since we would not understand what in the picture reflects certain audio parameters. Of course we could actually modify audio data with graphical effects but again, our outcome would exist only in frame of noise variations. One of the reasons that for lies in the fact that our X and Y axes would still represent only one dimension – time.
Spectrogram & FFT
In order to give some understandable meaning to audio data we need to convert the audio signal from-time domain into frequency-domain. And that can be achieved via windowed Fast Fourier Transform (FFT) or more accurately short-time Fourier transform (STFT). If we apply STFT to our vertical audio slices, the result would be a mirrored spectrogram (fig. 4b). That kind of graphical audio representation can be easily interpreted but has at the same time half of the unwanted data – the mirrored part. In order to obtain only the information we need we can simply remove the unneeded part (fig. 6), which in a way happens by default in Max’s pfft~ object. In other words, just as we have to avoid using frequencies above Nyquist in order to prevent aliasing in digital world, it is pointless to analyze audio all the way up to the sampling rate frequency since everything above Nyquist freq. will allways give us wrong results in form of mirrored spectrum.
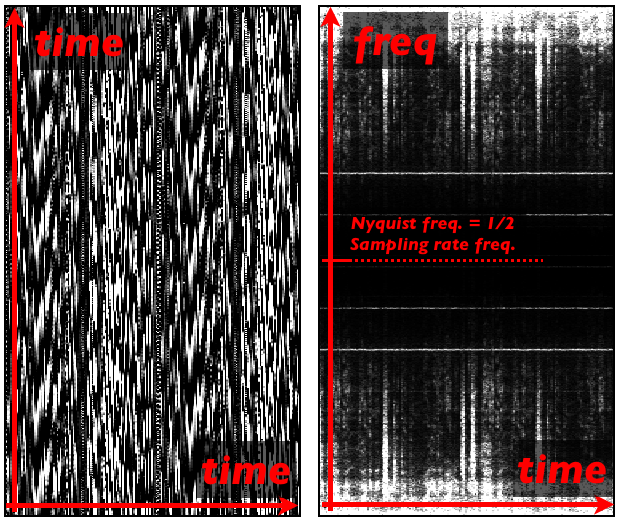
Figure 4a (right) Spectrogram or vertically plotted slices of audio (few words of speech) transformed into frequency-domain via STFT.
First step of STFT, which is the most common and useful form of FFT, is to apply a volume envelope to a time slice. Volume envelope could be a triangle or any symmetrical curve such as Gaussian, Hamming, etc. The volume envelope in question is in the world of signal analysis called a window function and the result, time slice multiplied by a window function, is called a window or a windowed segment. At the last stage of STFT, FFT is calculated for the windowed segment (fig. 5). At that point, FFT should be considered only as a mathematical function, that translates windowed fragments of time-domain signals into frequency-domain signals.
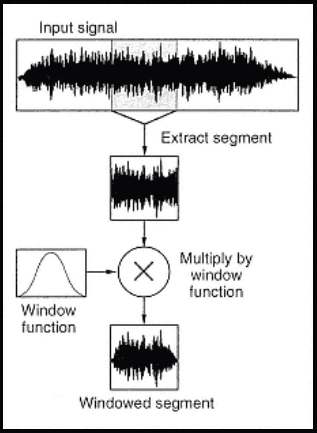
In order to perform STFT, windows have to consist of exactly 2^n (2 to the power of n) samples . That results in familiar numbers such as 128, 256, 512, 1024, 2048, 4096 etc. These numbers represent the FFT size or in our case, twice the height of a spectrogram image in pixels (fig. 6). At that point we can also further adopt the terminology from the world of FFT and call each column in the spectrogram matrix a FFT frame and each pixel inside the column a FFT bin. Therefore each useful half of FFT frame consists of 2^n/2 FFT bins, where 2^n is the number of samples in windowed segment. Number of FFT frames corresponds to the number of pixels in horizontal direction of an image (spectrogram) while number of half FFT bins correspond to the number of pixels in vertical direction. Hence: spectrogram image width = nr. of FFT frames; spectrogram image height = nr. of FFT bins divided by 2.
If our goal would be only to create a spectrogram, we would need to convert a linear frequency scale of our spectrogram into logarithmic one, in order to have a better view into the most important part of the spectrum. Also we would need to downsample or “squash” the height of our spectrogram image, since the images might be too high (4096 samples long window would give us 2048 vertical pixels on our spectrogram). Both actions would result in significant data loss that we can not afford when preparing the ground for further spectral transformations. Hence if we want to preserve all the data obtained during the FFT analysis, our linear spectral matrix should remain intact. Of course it would be sensible to duplicate and remap the spectral data, to create a user friendly interactive sonogram, through which one could interact with original spectral matrix, but that would complicate things even further so it will not be covered in this article. For now, the image of our spectrogram should consist of all the useful data obtained during the FFT analysis.
It is also important to emphasize that window size defines the lowest frequency that can be detected in time-domain signal by FFT. That frequency is called a fundamental FFT frequency. As we know, frequency and wavelength are in reverse relationship, therefore very low frequencies have very large wavelengths or periods. And if the period is bigger than our chosen window, so it can not fit inside the window, it can not be detected by the FFT algorithm. Hence we need large windows in order to analyze low frequencies. Large windows also give us a good frequency resolution of frequency-domain signals. The reason for that lies in the harmonic nature of FFT.
FFT can be considered as a harmonically rich entity that consists of many harmonically related sine waves. First sine wave is a FFT fundamental. For instance if we would choose 2^9, or 512, samples long window at the sampling rate of 44.1kHz, our FFT fundamental would be 86.13Hz (44100Hz/512=86.13Hz). And all the following harmonics would have a frequency of , where N is an integer. All these virtual harmonics are basically FFT probes: FFT compares time-domain signal with each probe and checks if that frequency is also present in the tested signal. Hence smaller FFT fundamentals, as a consequence of larger windows, mean that we have much more FFT probes in the range from fundamental and all the way up to the Nyquist frequency. That is why large windows give us a good frequency resolution.
So if FFT probe detects the testing frequency in the time-domain signal, it tells us how strong it is (amplitude) and what is its phase. Since the number of probes always equals the number of samples in chosen time window, we get two information for each sample of time-domain audio signal – that is amplitude and phase. Hence the full spectrogram from figure 4b, without the unwanted mirrored part, actually looks like this (fig. 7):
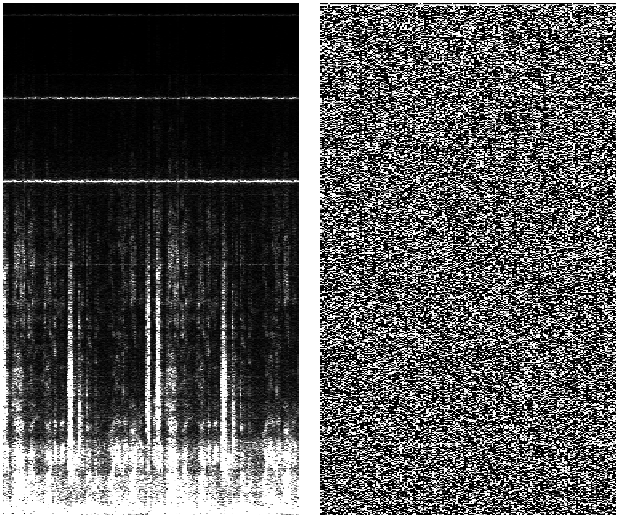
Figure 7 Graphical representation of amplitude (left) and phase (right) information of a frequency-domain signal.
We see that phase part of a spectrogram does not give us any meaningful information (*when we look at it) and is therefore usually not displayed. But as we will see later, the phase information is very important when processing spectral data and transforming it back into time-domain via inverse STFT and overlap-add (OA) resynthesis.
As we said, the size of the window defines the FFT fundamental and hence the frequency resolution of the FFT. Therefore we need big windows for good frequency resolution. But here comes the ultimate problem of FFT – frequency and time resolution are in inverse relationship. FFT frames (analyzed windows) are actually snapshots frozen in time. There is no temporal information about analyzed audio inside a single FFT frame. Therefore an audio signal in frequency-domain can be imagined as successive frames of a film. Just as each frame of a film is a static picture, each FFT frame presents in a way a “static” sound. And if we want to hear a single FFT frame we need to constantly loop through it, just as a digital oscillator loops through its wavetable. Therefore a sound of a FFT frame is “static” in a way that is “static” a sound of on oscillator with a constant frequency. For a good temporal resolution we therefore need to sacrifice the frequency resolution and vice-versa.
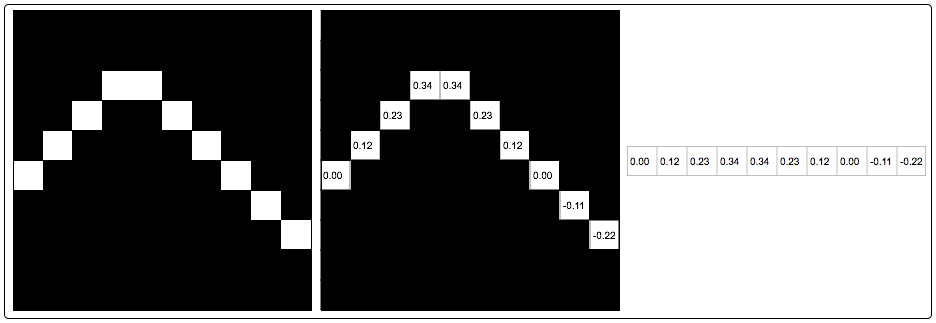
STFT is in praxis always performed with overlapping windows. One function of overlapping windows is to cancel out the unwanted artifacts of amplitude modulation that occurs when applying a window to a time slice. As we can see from figure 8, overlapping factor 2 is sufficient for that job. The sum of overlapping window amplitudes is constantly 1, which cancels out the effect of amplitude modulation. Hence we can conclude that our spectrogram from figure 7 is not very accurate, since we haven’t used any overlap.
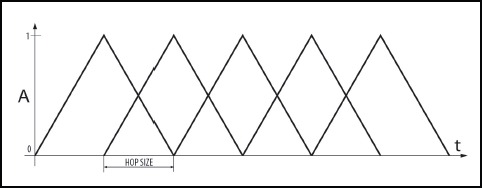
Figure 8 Windowing with triangular window functions with overlap factor 2. The sum of overlapping window amplitudes is constantly 1, which cancels out the effect of amplitude modulation.
Another role of overlapping is to increase the time resolution of frequency-domain signals. According to Curtis Roads, “an overlap factor of eight or more is recommended when the goal is transforming the input signal” (Roads, 1996, p.555).
When using for instance overlap 8, it means that FFT is producing 8 times more data as when using no overlap – instead of one FFT frame we have 8 FFT frames. Therefore if we would like to present the same amount of time-domain signal in a spectrogram as in figure 6, we would need 8 times wider image (spectrogram). Also the sampling rate of all the FFT operations has to be overlap-times higher as in the time-domain part of our patch or a program (*in case we want to process all the data in real-time).
Now as we introduced the concept of spectrogram, it is time to take a look into the central tool of sonographic sound processing, the phase vocoder.
Phase Vocoder
Phase vocoder (PV) can be considered as an upgrade to STFT and is consequentially a very popular analysis tool. The added benefit is that it can measure a frequency deviation from its center bin frequency as said by Dodge and Jerse (1997, p. 251). For example if the STFT with fundamental frequency 100Hz is analyzing a 980Hz sine tone, the FFT algorithm would show the biggest energy in bin with index 10 – in other words at the frequency 1000Hz. PV is on the other hand able to determine that the greatest energy was concentrated -20Hz below the 1000Hz bin giving us the correct result 980Hz.
Calculation of mentioned frequency deviation is based on phase differences between successive FFT frames for a given FFT bin. In other words, phase differences are calculated between neighboring pixels for each row in spectral matrix containing phase information (fig 7, right). In general, phase vocoder does not store spectral data in a form of a spectrogram but in form of a linear stereo buffer (one channel for phase and the other one for amplitude).
Phase hence contains a structural information or information about temporal development of a sound. ”The phase relationships between the different bins will reconstruct time-limited events when the time domain representation is resynthesized” (Sprenger, 1999). Bin’s true frequency therefore enables a reconstruction of time domain signal on a different time basis (1999). In other words, phase difference and consequently a running phase is what enables a smooth time stretching or time compression in phase vocoder. Time stretching or time compression in the case of our phase vocoder with spectrogram as an interface, is actually its ability to read the FFT data (spectrogram) with various reading speeds while preserving the initial pitch.
Since inverse FFT demands phase for signal reconstruction instead of phase difference, phase difference has to be summed back together and this is called a running phase. If there is no time manipulation present (*reading speed = the speed of recording), running phase for each frequency bin equals phase values obtained straight after the analysis. But for any different reading speed running phase is different from initial phases and responsible for smooth signal reconstruction. And taking phase into consideration when resynthesizing time stretched audio signals is the main difference between phase vocoder and synchronous granular synthesis (SGS).
As soon as we have a phase vocoder with spectrogram as an interface, and when our spectrogram actually reflects the actual FFT data, so all the pixels represent all useful FFT data (*we can ignore mirrored spectrum), we are ready to perform sonographic sound processing. We can record our spectral data, in form of two gray scale spectral images (amplitude and phase), import them into Photoshop or any similar image processing software and playback the modified images as sounds. We just need to know what sizes to use for our chosen FFT parameters. But when we are preforming spectral sound processing in real-time programming environments such as Max/Jitter, we can modify our spectrograms “on the fly”. Jitter offer us endless possibilities of real-time graphical manipulations so we can tweak our spectrogram with graphical effects just like we would tweak our synth parameters in real-time. And the commodity of real-time sonographic interaction is very rear in the world of sonographic sound processing. Actually I am not aware of any commercial sonographic processing product on the market, that would enable user a real-time interaction.
Bits ,GPU and Interpolation
Another important thing when graphically modifying sound is to preserve the bit resolution of audio when processing images. Audio signals have accuracy of 32 bit floating point or more. On the other hand, a single channel of ARGB color model, has the resolution of only 8 bits. And since we are using gray scale images, we only use one channel. Hence we need to process our spectrogram images only with objects or tools, that are able to process 32 or 64 bit floating point numbers.
When doing spectral processing is also sensible to consider processing of spectral data on GPUs, that are much more powerful and faster with their parallel processing abilities as CPUs. One may think that all image processing takes place on GPU but that is not correct in many cases. Many graphical effects are actually using CPU to scale and reposition the data of an image. So the idea is to transfer the spectral data from CPU to GPU, perform as many operations as possible on the GPU by using various shaders, and then transferring the spectrogram back to CPU where it can be converted back into time-domain signal.
The only problematic link in the chain, when transferring data from CPU to GPU and back, is the actual transfer to and from the graphics card. That is in general slowing the whole process to certain extent. Therefore we should have only one CPU-GPU-CPU transfer in the whole patch. Once on the GPU, all the desired openGL actions should be executed. Also we have to be careful that we do not loose our 32 bit resolution in the process, which happens in Max by default when going from GPU to CPU, because Jitter assumes that we need something in ARGB format from the GPU.
For the end of this article I should also mention one very useful method, discovered by J.F. Charles (Charles, 2008), and that is the interpolation between successive FFT frames. As we said earlier, FFT frames are like frames in a movie. Hence we progress through spectrogram, when reading it back, by jumping from one FFT frame to another. And in the same manner as we notice switching between successive still pictures when playing back a video very slowly, we notice switching between successive FFT frames (“static” loops) when reading a spectrogram back very slowly. And that is known as frame effect of phase vocoder. Hence in order to achieve a high quality read back when doing extreme time stretching, we can constantly interpolate between two successive FFT frames and read only the interpolated one.
References
Charles, J. F. 2008. A Tutorial on Spectral Sound Processing Using Max/MSP and Jitter. Computer Music Journal 32(3) pp. 87–102.
Dodge, C. and Jerse, T.A. 1997. Computer Music: Synthesis, Composition and Performance. 2nd edition, New York: Thomson Learning
Roads, C. 1996. The Computer Music Tutorial. Cambridge, Massachusetts: The MIT Press
Sprenger, S. M. 1999. Pitch Scaling Using The Fourier Transform. Audio DSP pages. [Online Book]. Available: http://docs.happycoders.org/unsorted/computer_science/digital_signal_processing/dspdimension.pdf [Accessed 5 August 2010].
Tadej Droljc, spring 2013
This article was graciously contributed by Tadej Droljc. A .Zip compressed copy of his thesis, along with many Max/MSP patches, is available for download from his personal site. Guest contributions are always welcome on Designing Sound. If you have an idea you’d like to share, then contact shaun [at] designingsound [dot] org.
Thanks again for sharing this, I caught it on the C74 forums, but it’s nice to have an overview on here.
Really inspiring work.