When building the space that sounds occupy, it may sometimes seem like overkill to load up those DSP hungry (though wonderful) reverb plug-ins. They can be a pretty big load when it comes to even the mildest amount of spatialization, and it can also be time consuming to configure one to emulate an outdoor space. I thought it would be worth sharing a trick of mine for both situations. A low-to-no DSP method of spatialization that allows us to “fake the space.” I should qualify this. We aren’t going to be looking at how to fake a traditional reverb, but how to add a mild sense of space to the sounds we work with. We’re just going to give them a little bit of multichannel presence to better situate them in the world. Before I get into the specifics of the process though, let’s review some science!
The laws that we’re going to be using are a combination of biology and psychology, with a touch of physics. The study of how we hear and perceive acoustic events is termed Psychoacoustics, and we’ll specifically be taking a quick look at what is known about “delays” and their integration with direct-source sounds. This is, after all, all reverberation is…the ratio between the direct onset of a sonic event and the multiple reflections (delayed onsets) of that event at the ear.
So let’s talk about what happens when we hear a mixture of direct and reflected sounds. There are four time values you’ll want to remember: 10ms, 35ms, 50ms, and 100ms. In decimal form, because the numbers will be useful when it comes time to use them in a DAW, the numbers are: 0.010, 0.035, 0.050 and 0.1 seconds.
Let’s begin with the numbers that are significant to the perception of reverb. At delays of 35ms, we begin to perceive reflections as echos of the direct (or original) sound. This is what our reverb plug-ins refer to when they mention “early reflections,” and the range they occupy extends to 50ms. 50ms is where “late reflections” begin, and they extend to approximately 100ms. Though truly discrete echos are in the neighborhood of 80ms and later, all onsets within these ranges can be considered echos and help us interpret the enclosing space. These reflections tell us how far we are from the sound source, how large the room is and, depending on the ratio of direct to reflected sound, can tell us where the sound source is in the space. It is the density and diffusion of all of these reflections that transform echos into reverb. Diffuse reflections that occur later than 100ms are what defines the decay characteristics of that space. We call the room “live” sounding if there is a lot of activity, and “dry” if there is little or no activity.
An effect that occurs when he hear a mixture of direct and delayed sounds is comb filtering. It occurs at all of the values I listed earlier…as well as the ranges between them, of course…though it is most noticeable when the delay is small. In the range of 1-10 ms, comb filtering is heavily audible. In fact, delay sweeps in this range are how phasing plug-ins create their unique sounds. Unless that’s your goal, and it’s not in our current discussion, it’s best to avoid the combination of direct and reflected sounds in this range.
So, what about that range between 10 and 35ms? What’s so special about this range that I haven’t mentioned yet? Well, this is where the “Haas Effect” exists. The Haas Effect, naturally, named for the scientist that identified it, Helmut Haas. It is the name for the behavior of integration that occurs with any reflections/delays of less than 35ms. [note: This includes 0-10ms, but we’re going to ignore that range because of the heavy comb-filtering that occurs there.] Simply put, our brains interpret any reflection or delayed sounds that occurs less than 35ms after the direct sound as part of that sound.
Now let’s get into the meat of it. As an example, consider sound A, which is in our left channel. Say we route it to the right channel with a delay between 10 and 35ms. Let’s call this delayed route sound B. When A and B are played back, our brain will interpret sound A as the source. In some cases sound B could be louder, and sound A will still be interpreted as the source of the sound. That’s right. In spite of the level imbalance that would make you think that you’ll hear two discretely panned sounds, you’ll actually hear only one panned sound.
Naturally, there are a few cavéats that we’ll need to note. Let’s save that for later and take a look at a specific example. I’m going to start out with the sound of a car from a drag race. I pulled it into Pro Tools, panned it hard left (I’m going to refer to this as Car A), and bounced it out as a stereo file. This way, we can listen to it as a mono source with no reverb/spatialization in the right channel.
Car A panned hard left in a stereo audio file with no spatialization…on SoundCloud
[Apologies for the link out, we’re still having issues with the embedded SoundCloud player.]
To continue, I duplicated the file to a second track (I’m going to refer to this as Car B). I then shifted the duplicate to start 29ms after the original, and dropped it by 12.5dB. No DSP whatsoever so far.
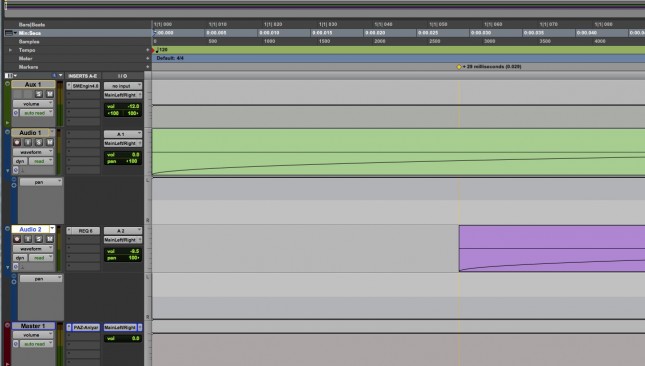
Car A duplicated and delayed, becoming Car B, panned hard right…on SoundCloud
Next, I wanted to de-correlate the sound a bit to enhance the illusion. So, I added an EQ to Car B. I also increased the level of Car B to -9.5dB.
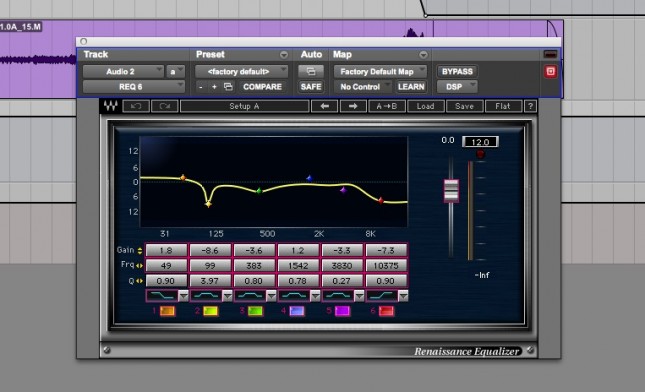
Cars hard panned with EQ on SoundCloud
This psychoacoustic trick works with sounds that are panned over time with a stereo image as well. Here, I shifted both sounds to their opposite channels. If you’re going to do this, it’s important to make sure that the timing of the image shift between the sounds is either exact or close. Having that simultaneity helps fool our brains into integrating the two sounds as one.

Simultaneous stereo panning of Car A and Car B on SoundCloud
And just to prove my point that, at times, sound B can be louder than sound A, here is a repeat of the last audio file. This time Car B is +3.0dB compared to Car A. This is right on the psychoacoustic line for integration (fusing of sounds) despite level differences, and the illusion almost falls apart in the beginning. Remember that Car A (the earlier sound) is panning from left to right, while Car B is panning from right to left.
Stereo pan with level balance favoring Car B on SoundCloud
So, I’ve successfully created space around this car, and the only DSP I’ve used is that required for the EQ. I didn’t even have to use that, it just helped sell the experience. This technique is one I typically use when I have mono production audio, from an outdoor space, that I need to put into a multi-channel (stereo or 5.1) mix. Yes, I have used it great effect in 5.1 mixes. It helps sit the sound within an ambient space, utilizing the characteristics of the original space.
As I’ve mentioned, there are a few cavéats we should cover:
1. Don’t be confused about what is capable with this technique. It only works with what is already there. You’re not going to be able to create large spaces or long decay times if they don’t exist in the original recording.
2. Despite the psychoacoustic principles, watch out for phase effects. They can still pop up if you’re not careful. It’s a good idea to sum all the channels you’re using down to mono as a confidence check. While in mono, place the original sound in and out of solo. If there’s strange coloration happening when everything is summing, you’ve probably pushed it too far somewhere along the line. It’s even more important to check this in mixes larger than stereo, because of the way dodgy phase can sometimes affect channel distribution after a decode. If you’ve got the capability, do a check with the audio passing through an encoder-decoder pair before committing to the technique within your mix.
3. There’s a minimum duration of the original sound required, and transient sounds don’t always work so well. Those that are composed of cyclical transients can be even worse. For example, take a listen to the sound of the same engine idling.
Segregating idle on SoundCloud
Here, Car A and Car B were equal in level. While the left channel, Car A, still feels louder and dominant, the right channel , Car B, is perceived independent of Car A. Getting the two sounds to integrate requires the onset of the delayed sound to occur before the offset of the original. In the case above, we’d have to be within the 1-10ms window we’re trying to avoid.
4. There is a volume/level threshold required to maintain the illusion. In general, it’s best to keep A moderately louder than B, but if you want to experiment here are the psychoacoustic limits you need to maintain:
- 10ms – B should not be more than +4dB over A
- 20ms – B should not be more than +5dB over A
- 30ms – B should not be louder than A (0.0dB)
- 35ms – B should not be louder than -3.5dB below A
[note: The curve for these numbers is non-linear and is also affected by spectral content, which is why the level imbalance in sound file #5 is border-line despite it being +3dB. If you’d like to read more about this, the data comes from Peter Mapp’s “Designing for Speech Intellgibility” in Focal Press’ Handbook for Sound Engineers: 4th Edition, page 1398]
5. The closer you get to those magic numbers of 10 and 35 milliseconds, the more likely you are to fail using this technique. For that reason, I tend to stay at least 5ms away from those extremes. Experiment with the timing to find the best delay between 15ms and 30ms.
Those are the five key points to keep in mind when utilizing this technique. Don’t take my word for it though, experiment a bit for yourself and share the results. I’m sure you’ll find it useful somewhere. ;)
Cool article, Shaun.
I normally work in the film frame grid in PT, at 24 fps, where one frame is 41.66 ms, so it’s really easy to nudge in quarter frames. So for me a quick way to try some different delays out is to nudge the ambient track one (10.41ms), two (20.83ms), or three (31.25ms) quarter frames of delay (to fall within your recommended delay window). Because of the speed of sound, each quarter frame is about a twelve foot further push away for the ambient track, so the amount of delay is related to the illusion of size. I like your de-correlation idea, too. The stereoeqpan track does sound good. Nice fake!
Thanks for the kind words, Douglas. Those are some great points, too. I work a lot on television material in both PAL and NTSC. Because I’m frequently jumping back and forth between the two, it’s important for me to keep the absolute values in mind so that I don’t muck it all up. Thanks for providing that other point of reference!
Down with reverb! Down with Reverb. We want morphing!! We want morph stuff. Reverb month protest here. Down with Reverbs!! We want morphing!
I need a Sound Morphing month where you give us some incite on stuff like Symbolic Sound Paca-whatever, Prosoniq Morph, etc. I need to know more about morphing sound……..Uhmm Please.
Thanks !
It pushed me back to use Haas effect.
I tried this in the 0-10ms comb-filtering region for a simple reason : i worked only with instruments ;)
Too much troubles with combfiltering…
And when you are over 10ms with an instrument, the delay is so obvious there is no more space effect.Even more with transients (like you said).
You clearly hear that “slapback” effect.
I ended up thinking it is useless with instruments.
I prefer some stereo chorus (things like Stereoizer Hbasm ).
I will try back with FX and other non musical material now ;)
What is the best method for faking a non morphing stereo file with a single mono source? Typically I duplicate the mono file to hard L & R and nudge one side a small amount, maybe 5-10ms. Is that right? Thanks for the article btw.
I forgot to mention that I invert the phase on one of the sides.
Great article..I will be playing with this!
Can’t wait to try this! Thanks for the great article.